Until a few years ago, few of us had ever heard of data science. Can you give us a quick snapshot of its history? People have been using the algorithms & statistical solutions for 25 years or more, but data science was first coined as a business term in 2012, and the first data science teams came about with the explosion of data, when companies started to think about being data driven and digital first.
Once the data became available, companies started to think about making their decisions based on data, and analysts and data scientists began to make that data easy to analyse and consume.
There have been academic conferences on data mining for 30 years, it’s not a new thing, but when you put engineering on top of the statistical algorithms you get what we now call data science. Big companies pushed for this, and there was a lot of return on investment for them as a result.
2. How do you help a company move to using data to drive decision making?
It’s easy for the smaller tech-enabled digital start-ups, because you don’t have to push for cultural change. Data driven thinking is already embedded, so even if they grow, they already have it in their DNA.
For enterprise businesses it’s harder; they weren’t born relying on data and they didn’t use the data they had. For some banks, or telecoms companies it hasn’t been core or central to what they do, so they haven’t been storing their data, and even if they did store it, they might not have put that data into a form that they could then analyse.
Where data is not core, or fundamental to the business, it’s difficult to encourage change with decision makers. You need to help them understand why they need it, why leading competitors are using it, how it will drive ROI, and you need to give them concrete steps on how to do it. It might be a big change for some businesses. You have to embrace the chaos that data can bring to the process – the world is chaotic, and nothing is definite or static. Agile and other methodologies are also based on a changing world, and you need to embrace that.
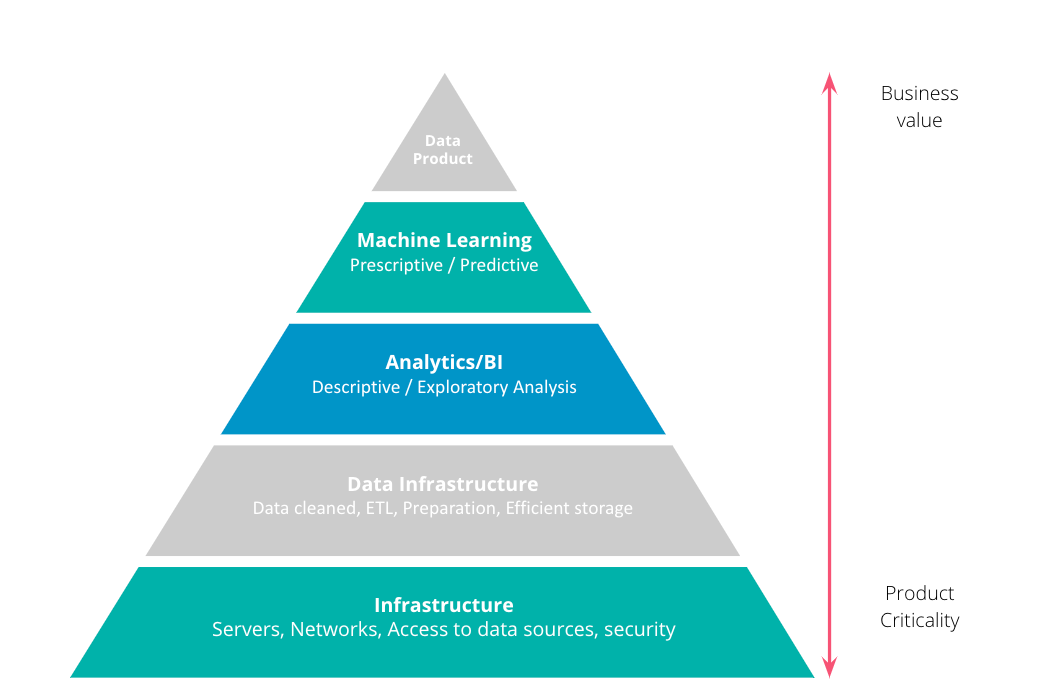
End to End Data Product 3. Walk us through a typical day in your life working as a Data Scientist?
I manage 2 teams on 2 projects in the financial tech sector, in one project we use machine learning algorithms to cluster people based on the probability of fraud and debt default, which feeds other algorithms that make decisions on business questions for loan insurers, such as when will they default.
The other project looks at cash supply change management at money transfer outlets, deciding how much money to send to outlets and how much to keep in stock, looking at the financial risk of having too much or not enough money at the outlets day to day.
4. What's the biggest challenge the industry is currently facing with Covid19?
Lots of projects are halting, especially in start-ups supported by venture capitalists who might be withholding funding. For the big enterprises, if the project is core, such as decision making on where to distribute loans, the projects are still going ahead.
There’s been a big shift of attention to Covid, and everyone is shifting tools to tackle Covid, but there are no big launches or statements, and no new tools of frameworks so far. Analysis is going up however, as everyone is analysing the data. For the day to day counts I am currently using oxford university’s ourworldindata.org.
The problem is that there’s a lot of noise everywhere currently and a confusion of science without peer review or acceptable methods, so we don’t have that deeper analysis yet. Everyone is trying to help, so there’s no malice, but you really need domain knowledge of what you’re working on, because it’s very hard to predict without hypothesis or evaluation around it.
I’ve been reading some epidemiological papers from Imperial university and the London School of Economics, but even they have been using retracted scientific methods to get to the data and they’ve encountered mistakes. It’s hard to get accurate predictions on Covid19, because of mistakes in the method, but it’s great that people are trying to help and that it’s an open source community sharing data and methods. In time they’ll get to something better.
5. Tell us a bit about Mutt Data & what you do
We build automated data products, with prediction and statistical algorithms, with a focus on adding business value. We start with the business problems and gather internal and external data to give a measure of the business' performance. If it’s a big company with millions of users you can have a huge return on investment when you improve any metric and multiply that by the user base. It’s cheap to get infrastructure going with cloud providers nowadays, and you only pay for what you use, so it’s very convenient and mostly open source. Most of the costs go on development.
Mutt Data logo 6. What’s the biggest lesson you've learned on the job?
For me it’s the human part, the soft skills where I’ve learned the most, not the scientific part of my job. Computers and algorithms work, but misalignment and poor communication don’t work at all.
The culture of a business is crucial, and communication is very important. There are a lot of cues and implicit information in a team that we need to make sure is shared with everyone, especially when working remotely.
There are lots of expectations from the client, and external expectations, so you need to be very clear about what can and can’t be done in the time frame. All those details are crucial in any project, and a good work culture exists when collaboration is fostered. There needs to be an understanding and belief that the changes you are making are for the better, and that has to be shared by the team, and by stakeholders too.
7. What impact do you think AI and automation may have on data science in the next 10 years?
Most companies have yet to transition to AI, and the rate of failure is high so there is definitely room for improvement as well as a lot of low hanging fruit. Simple, non-specialised tasks can be augmented or complemented with AI and machine learning. In AI there’s a big impact on machine learning and improvements on explainability of algorithms, for example if you request a loan, imagine you are talking to a machine that can either allow or deny the loan, but you want to know why; there are currently few that can give you reasons.
It’s correlation not causality, so the AI understands that if it is raining things will get wet, so if the floor is wet it’s raining, but they don’t understand the causality. If you put a cow in the water at the beach they will check objects in likely places, not unusual places, so the AI will think it’s a manatee because it correlates the water with certain types of animal. What you need is an algorithm that understands causality.
8. What do you live for outside of the office during Covid19?
I’ve started working out again after a few years and doing a little bit of yoga. The lockdown is very strict where I’m based so everyone is inside.
9. What would you tell someone thinking of joining Hyerhub?
Hyerhub's resource management platform Hubbado is easier to use than others out there. It’s a competitive market but the job rates are very competitive, and the Hubbado site works for experts and professionals.
Mateo De Monasterio Mateo is a data scientist and mathematician with a methodical and critical vision using applied maths and software engineering best practices in his work.
He is also one of the founding members of Hyerhub partner company Mutt Data, a big data, data science, machine learning, and data products company that works with enterprises and start ups providing a number of services.
View the Mutt Data sales deck to learn more about their Big Data, Machine Learning and Data Product solutions, or get in touch
Sign up for Business and IT stories, articles and interviews - Hyerhub Blog Hyerhub blog - articles and case studies in Cyber Security, IT Networks, DevOps, IT Infrastructure, IR35, Sales, Project Management, Resourcing, Software Development, UX/UI and more
No spam. Unsubscribe anytime.